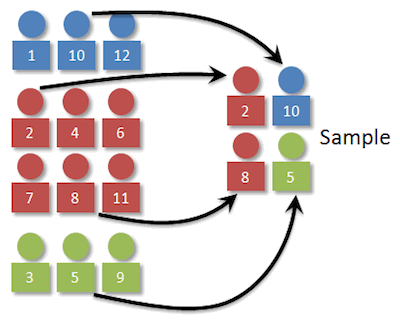
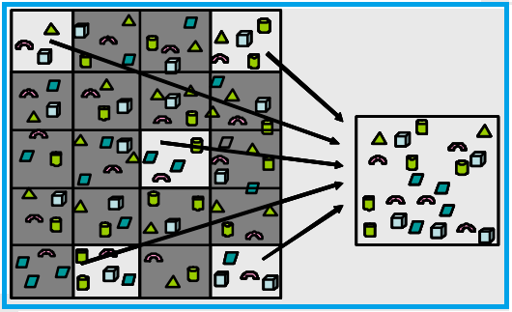
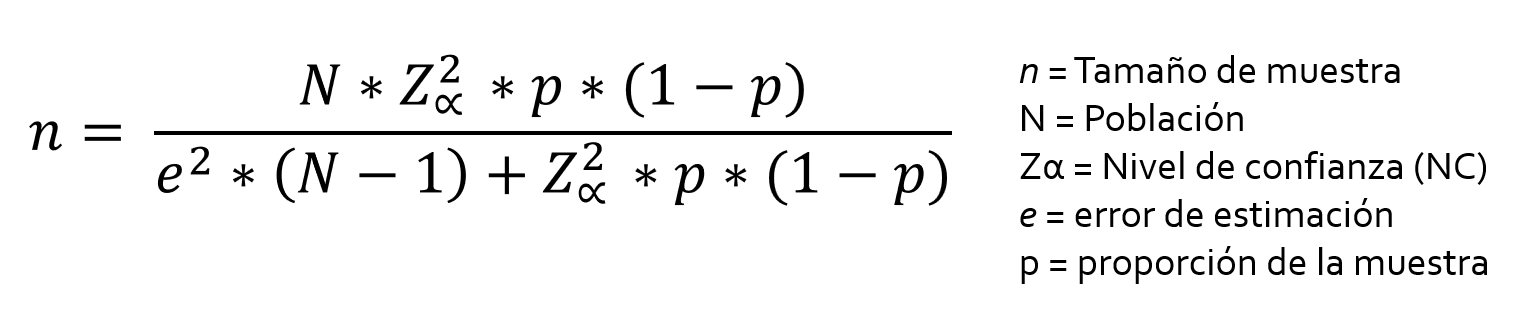representación adecuada de la población, de manera que se reproduzcan los rasgos esenciales de lo que se investiga
qué parte de una población debe seleccionarse?
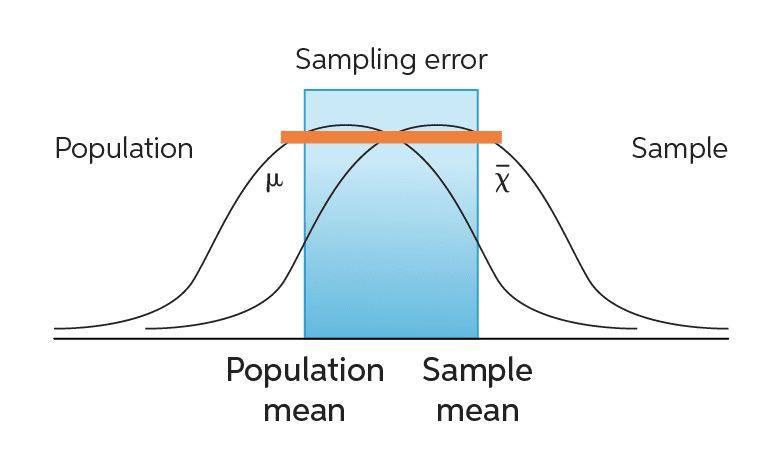
inferencias adecuadas
composición de la muestra
Población: conjunto de los casos que comparten las características que queremos generalizar (universo)
Unidad de observación: elemento sobre el cual se realiza la medición
Marco muestral: listado de unidades de muestreo (censo: listado de hogares, individuos…)
Muestra: Subgrupo de la población de interés sobre el cual se recolectarán los datos
tipos de muestra
probabilístico (aleatorio): Todos los elementos de la población tienen la misma posibilidad de ser escogidos. La selección es aleatoria y su número depende del tamaño de la población.
no probabilístico: depende del proceso de toma de decisiones de un/a investigador/a, los criterios de investigación y la posibilidad de acceder a las unidades de análisis
muestreo probabilístico aleatorio
- condiciones:
- La población ha de ser lo suficientemente grande.
- Todos los sujetos han de tener la misma posibilidad de ser escogidos para la muestra.
- Tipos de muestreo probabilístico/aleatorio:
- Simple
- Sistemático
- Estratificado
- Por etapas
- Cuando no se puede garantizar la aleatoriedad se realizan muestreos de tipo pseudoaleatorios: por áreas, cuotas e intencionales.
muestreo aleatorio simple
selección al azar (1 a n, sorteo)
marco muestral adecuado (debemos conocer la población)
no adecuado para poblaciones heterogéneas (con sub-grupos diferentes entre sí)
con reemplazo o sin reemplazo: una vez seleccionado un individuo se reintegra a la población original o no.
muestreo aleatorio sistemático
Se selecciona un punto aleatorio al inicio y posteriormente se elige a cada \(k\)-ésimo miembro de la población
Tras seleccionar al primer elemento de la población se suma el valor de K para obtener el segundo elemento y así hasta completar la muestra.
qué pasa cuando tenemos pobalciones que tienen grupos con diferentes caracteríticas?
muestreo aleatorio estratificado
La población se divide en estratos (población con determinadas características) y se selecciona de forma aleatoria una muestra de cada estrato
forma de definir los estratos: afijación
La variable elegida para formar los estratos no debe permitir que un individuo o elemento de la población pertenezca a más de uno de ellos
muestreo aleatorio estratificado
Afijación proporcionada: la muestra deberá tener estratos que guarden las mismas proporciones observadas en la población.
Afijación uniforme: cuando asignamos el mismo tamaño de muestra a todos los estratos definidos, sin importar el peso que tienen esos estratos en la población.
La muestra final será la que contemple todos los estratos
muestreo aleatorio por conglomerados (etapas)
Conglomerado: subdivisión pre-existente o natural de la población (provincia, instituto). Tiene que ser heterogéneo en sí mismo; idealmente contiene toda la variabilidad de la población.
aleatorio cuando son heterogéneos en sí mismos y homogéneos respecto a otros conglomerados
útil cuando no se dispone de una lista completa de la población a estudiar
estratificado vs conglomerado
![]()
meustreo pseudo-probabilístico
NO son aleatorios, aunque sí pueden ser representativos
cuando no se dispone de marco muestral o es difícil de conseguir
cuando las condiciones de la encuesta impiden realizar muestreos aleatorios
por cuotas
variación de estratificado
Se establecen estratos, que se suponen homogéneos y se asigna una cuota o tamaño de muestra de ese estrato (proporcional a la población).
no se hace a partir de un listado poblacional, sino que se deja al criterio del encuestador siempre que cumpla con las cuotas de cada estrato.
intencional
equipo investigador determina la muestra según su propio criterio, aunque siempre con la intención de obtener una muestra más o menos representativa de la población
cuando se carece de marco muestral y de información sobre la población estudiada
intentando minimizar los sesgos: igual número por sexo, edad, grupos sociales
errores de muestreo
tipos de errores
especificación de la población: no está clara la población que se necesita investigar
errror de selección: cuando los respondentes se auto-seleccionan (voluntarios)
marco muestral: se hace una muestra de una población equivocada
no respuesta: cuando no se obtiene respuestas con el instrumento
errores no muestrales
sesgos
Sujetos que son excluidos a priori de la muestra, es decir, que son parte de la población, pero no aparecen en el marco muestral
Fuentes de sesgo:
Mal diseño de la muestra
Mal diseño del instrumento (encuesta)
Unidad muestral “hogar”: sesgo de selección del respondente (padre…)
el tamaño
importa?
- Si es muy pequeña: puede no ser representativa de la población (incluir elementos o grupos desproporcionados) y sesgar los resultados
![]()
Si es muy grande: el estudio más complejo (demasiados datos) y costoso.
Puede ser una muestra más precisa, pero los costos superan a los beneficios.
muestra
![]()
muestra
tamaño: número de elementos necesario para conseguir una muestra lo más parecida posible a la población
Reducir el error al máximo posible
Conseguir una mayor representatividad (inferencia: que los resultados correspondan con los del universo poblacional)
objetivo
anatomía de una muestra
![]()
valores determinados en el diseño:
- \(\epsilon\): error, margen de error.
- ¿cuánto error voy a permitir en la muestra? en %
- \(Z\alpha\): nivel de confianza, valores Z y nivel de significación.
- ¿cuánto confío en que mis datos (media) esté dentro de ese margen de error? en %
- \(p\): proporción, desviación típica de la muestra.
- parámetro desconocido. maximiza \(n\) cuando es 0.5
más es mejor?
¿cuál es el tamaño de una muestra ideal para una población de 100 personas, con \(\epsilon\) = 0.05 y NC de 95%?
¿y para poblaciones de 1000, 10000, 100000?
¿cuál es el tamaño de muestra adecuado si quiero estudiar niveles de felicidad de estudiantes de la USAL con un NC de 95% y un \(\epsilon\) de 0.03? \(N\) = 28000
cálculo de muestras
y los estratos?
necesitamos la información del marco muestral (proporciones de estratos, por ejemplo)
se calculan el total de elementos para cada uno de los estratos, ya sea por afijación fija o proporcional:
- fija: \(n_h = N/h\) donde \(h\) es el nnúmero de estratos
- prporcional: \(n_h = \frac{N_h}{N}n\)
| Grado |
21191 |
| Doctorado |
2491 |
| Máster |
1923 |
| Título Propio |
1571 |
| Otro |
824 |
| Total |
28000 |