library(tidyverse)
library(haven)
e3207 <- read_sav("3207.sav")Limpieza de datos
Al trabajar con datos, existe un proceso previo que implica limpiar los datos. ¿hay datos faltantes/perdidos? ¿necesitamos crear nuevas variables? ¿alguna de ellas está descompesada? ¿necesitamos etiquetas para los datos nominales que observamos en forma de “numérica”?
Estos procedimientos pueden agruparse en lo que llamamos “limpieza de datos” y muchos dicen que es la parte más “engorrosa” del análisis.
frecuencias
Para saber cómo están estructurados nuestors datos es necesario conocer cómo están distribuidos.
(es implsercindible cargar nuestra base de datos a la carpeta de neustro proyecto.)
Un paso previo que es recomendable realizar es explorar las variables que vamos a utilizar en nuestro trabajo.
En nuestro ejemeplo, el Estudio 3207 del CIS tiene 2466 observaciones y 217 variables.
usando la función names() podemos saber los nombres de las variables de nuestra base de datos.
e3207 |> names() |> head()[1] "ESTU" "CUES" "CCAA" "PROV" "MUN" "TAMUNI"Estos nombres son poco útiles sin su respectivo libro de códigos o el cuestionario de la encuesta. A veces no contamos con ellos, pero podemos usar R para obtener las etiquetas de las variables (en caso de que existan).
install.packages("labelled")
library(labelled)
e3207 |> var_label() |> head()Es probable que no necesitemos todas las varaibles, por lo que podemos reducir el tamaño de nuestra base de datos seleccionando solo aquellas con las que vamos a trabajar. Esto facilita nuestro manejo de la base.
Para ello podemos usar la función select()
e3207 <- select(e3207, CUES, CCAA, P1, P26, P27, P29, P32, P33A, P34, P35, P37, P38, P39, P42)Ahora estamos en condiciones de obtener frecuencias de las varaibles que nos ineresan. Hay que recordar que una base de datos (en este caso un data.frame) se compone de columnas que indican las variables y filas que indican las observaciones. Si queremos obtener frecuencias, debemos indicar qué variable es la que nos interesa con el signo $.
Para obtener una tabla de frecuencias absoluta simplemente usamos el comando table().
table(e3207$P26)
0 1 2 3 4 5 6 7 8 9 10 98 99
91 92 232 297 214 544 297 362 254 44 23 9 7 Las frecuencias se pueden observar también mediante gráficos de barras. Para ello usamos la función barplot(). Hay que notar que barplot() se aplica a tablas, por lo que debemos crear un objeto a partir de nuestra tabla de frecuencias.
x <- table(e3207$P26)
barplot(x)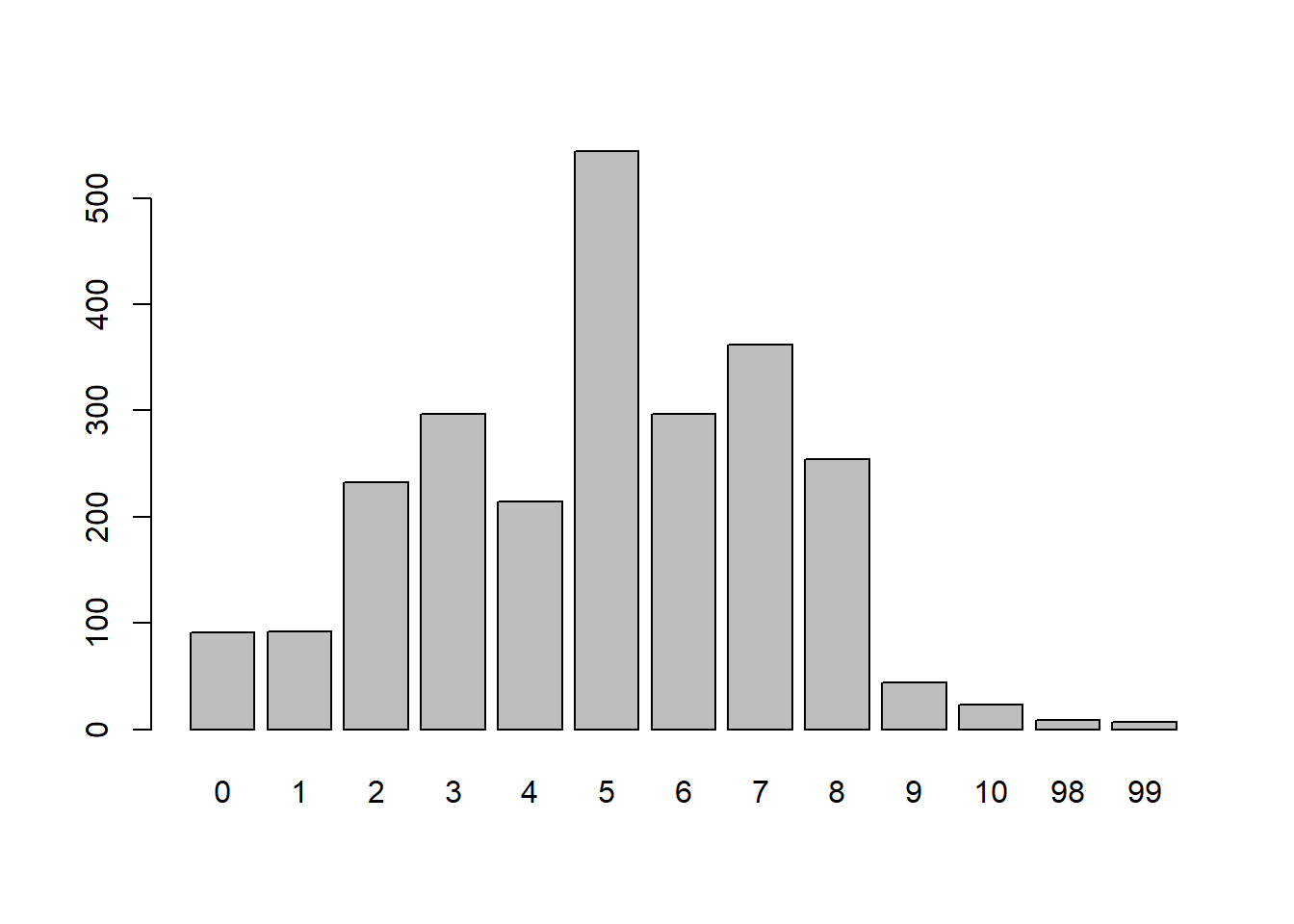
pocas veces usamos una tabla de frecuencias para una sola variable, lo común es cruzar dos (o más) variables. ¿cómo podemos hacerlo?
el comando table() permite usar como argumentos más de una variable.
ejercicio
quiero saber cómo se ve una tabla de frecuencias de las escalas de confianza y de la escala de egosísmo del estudio 3207 del CIS.
perdidos
¿qué podemos notar de las tablas de frecuencias? ¿qué pasaría si quisiera obtener la media con los valores dados por el CIS?

Usualmente cuando trabajamos con datos de fuentes externas debemos poner atención al tratamiento de datos perdidos.
En primer lugar es importante identificarlos. Suelen mostrar valores muy por fuera de la escala en que se mide una variable.
Por ejemplo en las preguntas sobre confianza y egoísmo, las escalas van de 0 a 10 (se puede comprobar mirando el cuestionario), sin embargo, algunas observaciones presentan casos con valores de 98 o 99. Es ideal tener a mano el libro de códigos para saber exactamente los valores que adoptan los datos perdidos.
La tabla de frecuencias nos ayuda a visualizar estos valores.
ejercicio
Identificar los valores que corresponden a datos perdidos en la pregunta sobre estado civil en la encuesta del CIS.
La siguiente tarea es reemplazar estos valores por algún tipo de dato que sea manejable por R (o por cualquier software que estemos usando, en SPSS por ejemplo, hicimos el ejercicio de “declarar” los datos perdidos).
Existen varias formas, pero la más usual es el comando na_if(). La “traducción” de este comando sería “asignar valores perdidos (na) si el valor observado (if) es…”
Este comando se aplica a vectores. Es decir, a cada variable y no al data.frame completo.
En R los valores perdidos se representan con las letras NA y no se computan cuando realizamos análisis.
#para reemplazar valores específicos por `NA` en una varaible debemos identificar la variable que va a cambiar, y luego aplicar la función na_if().
e3207$P26 <- na_if(e3207$P26, 98) #cambiar la variable P26 (vector) asgnando `NA` si aparece el valor 98 en el vector e3207$P26
e3207$P26 <- na_if(e3207$P26, 99)
e3207$P27 <- na_if(e3207$P27, 98)
e3207$P27 <- na_if(e3207$P27, 99)
e3207$P29 <- na_if(e3207$P29, 98)
e3207$P29 <- na_if(e3207$P29, 99)
e3207$P32 <- na_if(e3207$P32, 98)
e3207$P32 <- na_if(e3207$P32, 99)
e3207$P38 <- na_if(e3207$P38, 8)
e3207$P38 <- na_if(e3207$P38, 9)ejercicio
verificar si se aplicó bien el reemplazo de los valores perdidos.
identificar y reemplazar los datos perdidos en las variables “Valoración de la situación económica general de España” y “Escala de autoubicación ideológica (1-10)”
nueva variable
En la clase anterior ideamos la variable “buenrollismo” que era la suma de confianza y egoísmo (que sabemos que va en la misma dirección que confianza).
Para crear la variable buenrollismo en R únicamente debemos crear un nuevo “objeto” en nuestro data.frame que es la nueva variable, es decir, la suma de P26 y P27.
e3207$br <- e3207$P26 + e3207$P27et voilá…
recodificar variable
cuando queremos recodificar una variable en otra con menos categorías (por ejemplo rangos etarios), podemos usar findInterval() o cut()
head(findInterval(e3207$P35, c(1, 29, 49, 69, 98)))[1] 2 3 3 1 3 1head(cut(e3207$P35, c(1, 29, 49, 69, 98)))[1] (29,49] (49,69] (49,69] (1,29] (49,69] (1,29]
Levels: (1,29] (29,49] (49,69] (69,98]en caso de querer una nueva variable, debemos crearla:
e3207$edad4 <- cut(e3207$P35, c(1, 29, 49, 69, 98))